



股市配资什么意思 三只羊“财色录音”是假的,但背后技术是真的恐怖

黄金四小时线持续的大阴线实体,这种重锤下行,空军直接击穿,k线始终处于均线下方,k线始终被摁在地板上摩擦,反弹就是为了更好的空,日线级别依然也是看跌吞没,阴线实体直接击沉阳线,这是超级卖出走势,空,2498直接空
要说这段时间哪家公司风头正盛,那非三只羊莫属,隔三差五就要上一回新闻,还是法制栏目的那种。
这不前几天,月饼门的事件还没过去,又来了个录音门。
事情是这样的, 9 月 20 号的时候网上突然流传出了一段,疑似三只羊高管卢某的录音。
录音里涉及到了多位三只羊的女主播,具体内容咱在这就不多做讨论了,但确实很炸裂。。。

录音爆出来后,就在网上迅速引起了一波热度。有人说这段录音纯纯是男的喝多了吹的牛逼,但讨论的风向很快又变成了这玩意儿,到底是不是 AI 生成的,甚至还钓出来不少所谓的 AI 行家,开始一顿分析。
结果没两天,警方的通报就出来了:都散散吧,是 AI 干的。

而这次事件的另外一位主角, Reecho 睿声公司也终于浮出了水面,锤了自己的用户一把。
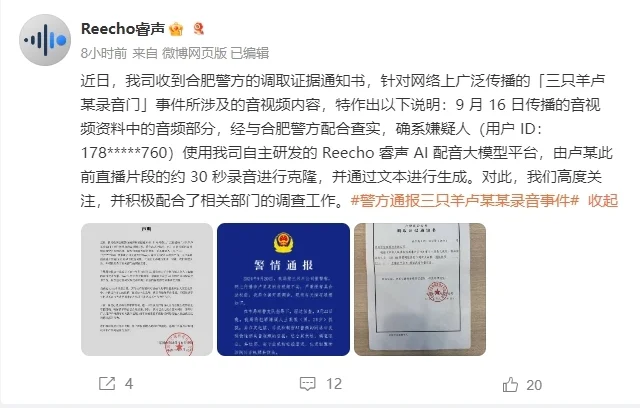
有意思的是,即使是官方都出面了,但还是有网友觉得卢某是 “ 酒后吐真言 ” ,通报也不过是把锅,甩给了没法儿自证的 AI 。
但不管咋说,人官方调查通报都出来了,你信也好不信也罢,这事儿就这么定调了。
不过以差评君对 AI 语音的了解,像三只羊录音门这种情况,的确是有可能的。主要是现阶段的 AI 语音技术,确实已经挺成熟的了。

因为我们只需要上传一两句话,剩下的直接甩给 AI 就行,分分钟就能克隆一个人的音色。
这么说吧,现在 AI 语音合成里比较常见、开源项目也比较多的,就数 TTS 、 SVC&RVC 两大类技术。
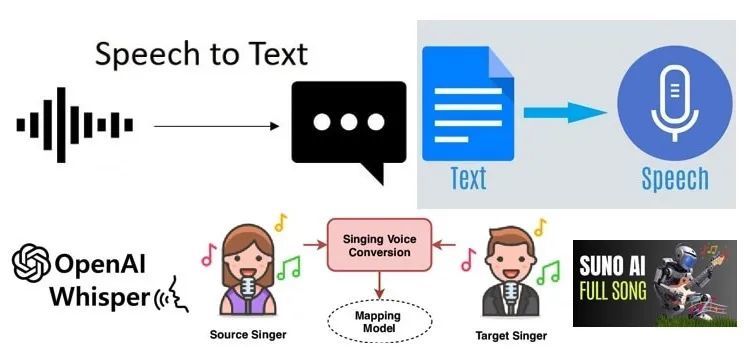
所谓 TTS ,简单来说就是 Text To Speech ,把文本转化成语音。像很多 AI 数字人、有声书、视频配音,大伙儿刷抖音经常听到的 “ 注意看,这个男人叫小帅 ” ,还有剪映素材库里那些 TVB 女声、广西表哥。。。基本都是 TTS 干的。
像这次三只羊录音门牵扯到的 Reecho 睿声,也是一个 TTS 模型的生成网站。咱们其实也在他们网站上,克隆过差评君的声优蛋蛋的声音,大伙儿可以听听看到底像不像。
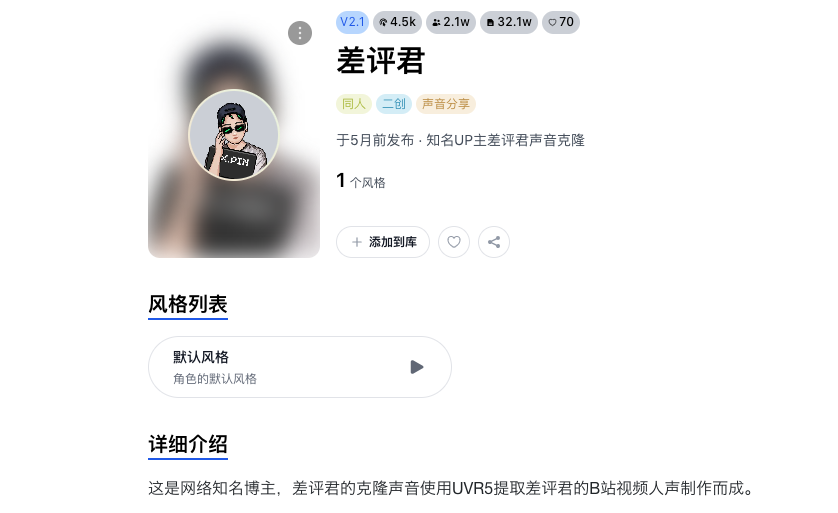
上来先用《 意大利面拌 42 号混凝土 》的 “ 名篇节选 ” 整一波,你别说,你还真别说。音色的复刻程度能有个 80%-90% ,而且说话的语气也贼像,不仔细听还以为在做什么正经科普。
打开新闻客户端 提升3倍流畅度我们本来还想借着 AI 差评君给大伙儿送一波福利,但没想到这个 AI 小小翻车了一下, 10 台 iPhone 16 说成了 “ 一零台 iPhone sixteen” 。。。穿帮的实在是太明显了,这福利想送都送不出去呀,可惜可惜。
借 AI 的口,你甚至还能听到差评君管广大差友们借钱。就连国庆节自愿加班 7 天,还不要加班费这种话,从这位 “AI 差评君 ” 的嘴里说出来,你也能听出心甘情愿的味道。
除此之外,人家那个声音市场里还可以自己选训练好的声音 AI ,不仅有我们的好朋友影视飓风 Tim ,甚至还有主播电棍,坤哥和派蒙,就连五星评论家麦克阿瑟也能拿来用。
有一说一,这种程度的克隆已经相当逼真了,所以现在回头看三只羊录音门,好像 AI 参与的可信度又高了一点。而有些朋友可能还觉得,那这个 AI 怎么就能把那种醉意、含糊不清的话都模拟出来呢?
这就得说到 SVC&RVC 了。这里面 SVC ( Singing Voice Conversion )是用来唱歌的,而 RVC ( Retrieval-based-Voice-Conversion )的场景多用在直播,这俩都是实时把语音转换成 AI 训练的音色,俗称变声器。
由于输入的是音频,所以它就能把一个人的声音转化的更真实,甚至连语气、声调这些东西都可以转化得很自然。如果是歌声转换,甚至还能模仿音色和唱腔。
像 GitHub 上有个叫 So-Vits-SVC 的开源项目,就一手打造了AI 孙燕姿、唱《 泪桥 》比原唱伍佰还好听的陶喆。
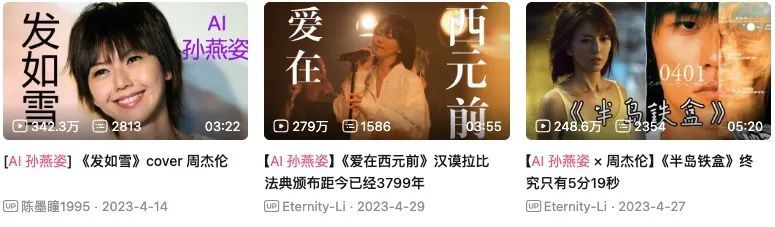
类似的开源项目还有很多,而且都很好上手。举个例子, b 站的大佬 “ 花儿不哭 ” 今年就上线了一个开源模型 GPT-SoVITs ,下载好直接拿语音喂就行了。
你要懒的自己训练,那还可以在魔搭社区用 “xz 乔希 ” 的项目直接开玩;甚至剪映和必剪这些剪辑软件里都已经用上了自家的 AI 语音,除了那些营销号语音你也可以生成自己的。
乃至于随便找个工具集合网站一搜,多得是可以直接上手用的产品。
我们之前用 “ 花儿不哭 ” 开源的 RVC 实时变声算法,也做过一个差评君变声器。
甚至还专门做了一个非常差评的初始界面。
至于效果大伙儿自个儿品吧,我打包票,这绝对不是隔壁差评君的声优蛋蛋录的。
而且当时我们还专门给变声器做了个硬件外挂,现在还搁办公室里呢。

人在这边对着麦说话,音响那边实时就能把声音变成蛋蛋的。
打开新闻客户端 提升3倍流畅度看起来挺牛逼是吧,不过这玩意也不是突然就这么先进了。
主要语音生成这一块确实低调,你就说这几年这些 AI 的宣传,一个个都好像是奔着炸裂全宇宙去的。三天两头画大饼,谁还惦记语音生成是怎么个情况。
关注的人少,再加上技术积累也多,那可不就是闷声发大财嘛。只不过现在突然出圈了,大家才感觉到惊奇。
说到底还是 AI 时代这些东西的门槛都降低了,你想 cos 哪个人的声线都相当方便。

不过实话,技术进步是一回事儿,但就事论事地说,用这玩意儿来违法犯罪的案例,并不在少数。
也不是咱制造啥恐慌,新华网去年九月就报道过了相关的诈骗手段,你想想家里年纪大的老人,要是接到跟你说话声音一模一样的诈骗电话,说你遇到了危险,会不会把棺材本都给骗子骗走?

不止国内,这事在国外照样有,就连美国知名密码管理工具公司 LastPass 的 CEO ,都被伪造声音拿去诈骗了。
尽管现在已经有不少机构在琢磨怎么处理安全问题,探索怎么识别伪造语音等证据,比如有研究表明,目前可以通过算法声纹认证和语音取证等办法,对 AI 合成语音进行鉴别。
但这些更多还是在找 AI 语音上的 bug 来鉴定的,就好像数手指和穿模来鉴定 AI 图片一样,只要模型一升级,这些办法可能就也没辙了。

不过差评君觉得,要从根本上解决问题,就还得从生成式模型本身出发。
给 AI 生成的图片、音视频也打上类似水印的标记,同时设备和软件也能够检索到这些标签,提醒大家这些内容并非真实。
像是谷歌就已经开始研究在 AI 生成的音频声谱上,添加能被视觉化的特定标记,这样既不会影响用户听感也方便识别。
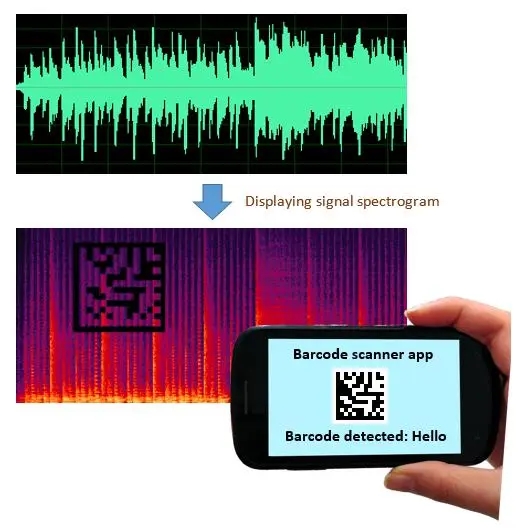
总的来说,在生成式 AI 的影响下,以后眼见不一定为实,耳听也可能为虚。归根结底技术在发展的同时,防范技术滥用的对策也必须做好。
别光想着说 “ 技术无罪 ” ,上个这么喊的人已经蹲了好多年,现在都出来了。
不过对三只羊来说,虽然始作俑者已经被抓,但这人靠 AI 推在他们身上这把劲股市配资什么意思,估计影响还会持续挺久,至于后续怎么发展,我们还是再等等看吧。